



GraphRAG Analysis, Part 1: How Indexing Elevates Vector Database Performance in RAG When Using Neo4j
A deep dive on Microsoft's GraphRAG paper found questionable metrics with vaguely defined lift, so I analyzed knowledge graphs in RAG overall using Neo4j vs FAISS

TLDR:
Note (emphasizing to address a comment) that Part 1 of this series compares the Neo4j vector database storage (as a baseline) to FAISS, and Part 2 compares the Neo4j Cypher-based graph creation and retrieval with FAISS vector database retrieval as a naive baseline. This notes any differences in the database retrieval themselves before comparing a knowledge graph to a naive baseline.
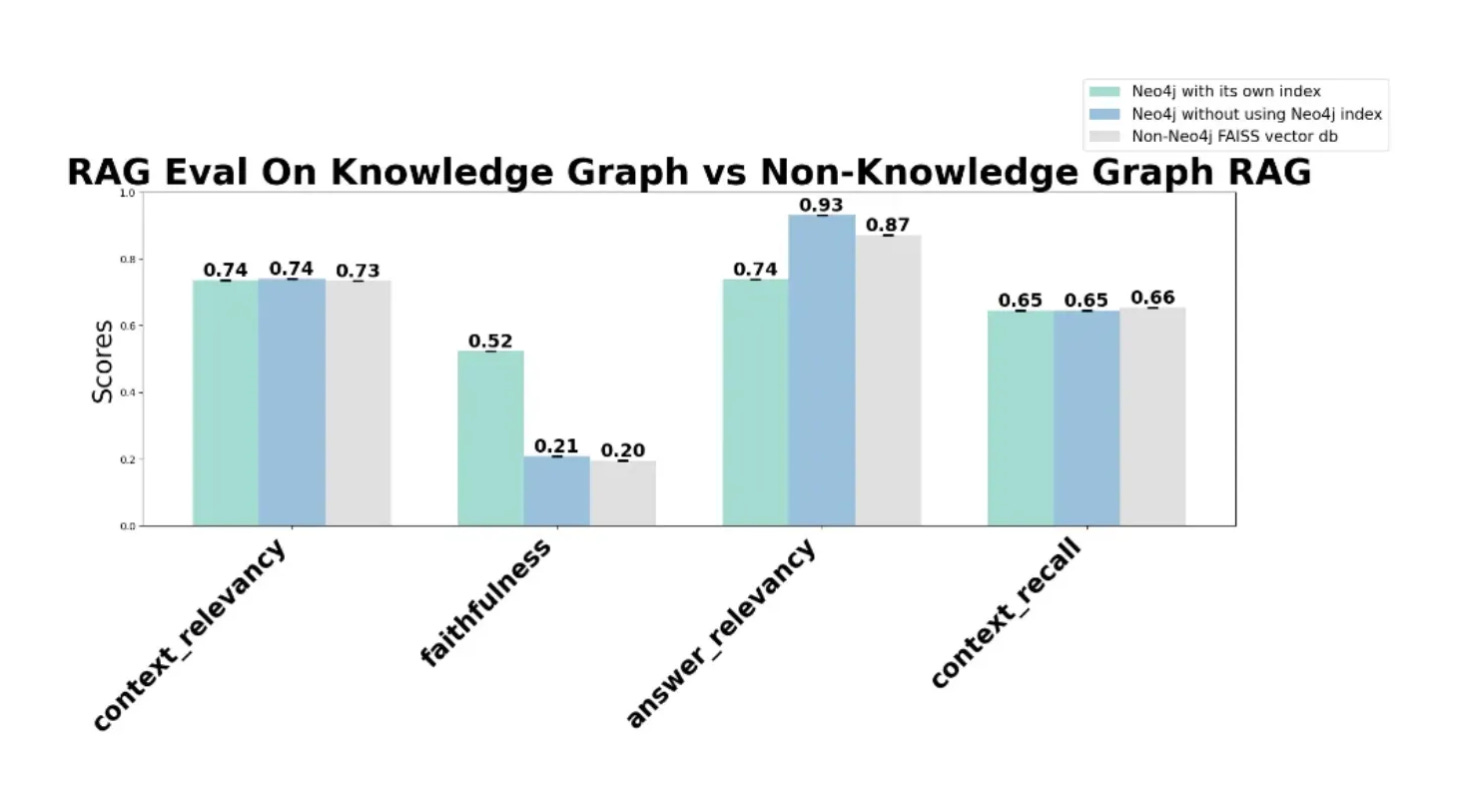
Neo4j vs FAISS vector database comparison may not significantly impact context retrieval, which allows for a good baseline with the nodes and edges that we’ll create with Neo4j in part 2 — the Neo4j vector database I examined showed similar context relevancy scores to those of FAISS (~0.74).
Neo4j vector database withOUT its own index achieves a higher answer relevancy score (0.93), but an 8% lift over FAISS may not be worth the ROI constraints. This score is compared to Neo4j vector db WITH index (0.74) and FAISS (0.87), suggesting potential benefits for applications requiring high-precision answers.
The faithfulness score improved significantly when using Neo4j’s index (0.52) compared to not using it (0.21) or using FAISS (0.20). This decreases fabricated information, and is of benefit but still throws a question for developers if using GraphRAG is worth ROI constraints (vs finetuning, which could cost slightly more but lead to much higher scores).
Chart showing Knowledge Graph to non-Knowledge Graph comparison (Part 1): the Neo4j vector database vs FAISS:
Original question that led to my analysis (and background):
If GraphRAG methods are as profound as the recent hype surrounding them, when and why would I use a knowledge graph in my RAG application?
I’ve been seeking to understand the practical applications of this technology beyond the currently hyped discussions, so I examined the original Microsoft research paper to gain a deeper understanding of their methodology and findings.
The 2 metrics the MSFT paper claims GraphRAG lifts:
Metric #1 - “Comprehensiveness”:
“How much detail does the answer provide to cover all aspects and details of the question?”
Recognizing that response level of detail can be influenced by various factors beyond knowledge graph implementation — the paper’s inclusion of a ‘Directness’ metric offers an interesting approach to controlling for response length, but I was surprised this was only one of the 2 metrics cited for lift, and was curious on other measures.
Metric #2 - “Diversity”:
“How varied and rich is the answer in providing different perspectives and insights on the question?”
The concept of diversity in responses presents a complex metric that may be influenced by various factors, including audience expectations and prompt design. This metric presents an interesting approach to evaluation, though for directly measuring knowledge graphs in RAG it may benefit from further refinement.
Was even more curious why lift magnitude is vague in the paper:
The paper’s official statement on reported lift of the 2 metrics above:
“substantial improvements over the naive RAG baseline”
The paper reports that GraphRAG, a newly open-sourced RAG pipeline, showed ‘substantial improvements’ over a ‘baseline‘. The vague nature of these terms sparked my interest in quantifying with more precision (taking into account all known biases of a measurement).
Due to the lack of specifics in their paper, I was inspired to conduct additional research to further explore the topic of knowledge graphs overall in RAG, first by comparing the Neo4j vector database with FAISS then by comparing the Neo4j knowledge graph with FAISS.
Note: Microsoft’s GraphRAG paper is downloadable here, but consider reviewing the following analysis as a complementary perspective that contains more relevant details to the paper’s findings.
Analysis methodology overview (Part 1):
Setup:
I split a PDF document into the same chunks for all variants of this analysis (The June 2024 US Presidential Debate transcript, an appropriate RAG opportunity for models created before that debate).
Loaded the document into Neo4j using its graphical representation of the semantic values it finds, and created a Neo4j index.
Created 3 retrievers to use as variants to test:
One using Neo4j knowledge graph AND the Neo4j index
Another using Neo4j knowledge graph WITHOUT the Neo4j index
A FAISS retriever baseline that loads the same document without ANY reference to Neo4j.
Then to evaluate:
Developed ground truth Q&A datasets to investigate potential scale-dependent effects on performance metrics.
Used RAGAS to evaluate results (precision and recall) of both the retrieval quality as well as the answer quality, which offer a complementary perspective to the metrics used in the Microsoft study.
Plotted the results below and caveat with biases.
Analysis:
Quick run through the code below — I’d used langchain, OpenAI for embeddings (and eval as well as retrieval), Neo4j and RAGAS:
# Ignore Warnings
import warnings
warnings.filterwarnings('ignore')
# Import packages
import os
import asyncio
import nest_asyncio
nest_asyncio.apply()
import pandas as pd
from dotenv import load_dotenv
from typing import List, Dict, Union
from scipy import stats
from collections import OrderedDict
import openai
from langchain_openai import OpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.text_splitter import TokenTextSplitter
from langchain_community.vectorstores import Neo4jVector, FAISS
from langchain_core.retrievers import BaseRetriever
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import Document
from neo4j import GraphDatabase
import numpy as np
import matplotlib.pyplot as plt
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_relevancy,
context_recall,
)
from datasets import Dataset
import randomAdded OpenAI API key from OAI and neo4j authentication from Neo4j:
# Set up API keys
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
neo4j_url = os.getenv("NEO4J_URL")
neo4j_user = os.getenv("NEO4J_USER")
neo4j_password = os.getenv("NEO4J_PASSWORD")
openai_api_key = os.getenv("OPENAI_API_KEY") # changed keys - ignore
# Load and process the PDF
pdf_path = "debate_transcript.pdf"
loader = PyPDFLoader(pdf_path)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) # Comparable to Neo4j
texts = text_splitter.split_documents(documents)
# Set up Neo4j connection
driver = GraphDatabase.driver(neo4j_url, auth=(neo4j_user, neo4j_password))Used Cypher to load into Neo4j and created a Neo4j index:
# Create function for vector index in Neo4j after the graph representation is complete below
def create_vector_index(tx):
query = """
CREATE VECTOR INDEX pdf_content_index IF NOT EXISTS
FOR (c:Content)
ON (c.embedding)
OPTIONS {indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}
"""
tx.run(query)
# Function for Neo4j graph creation
def create_document_graph(tx, texts, pdf_name):
query = """
MERGE (d:Document {name: $pdf_name})
WITH d
UNWIND $texts AS text
CREATE (c:Content {text: text.page_content, page: text.metadata.page})
CREATE (d)-[:HAS_CONTENT]->(c)
WITH c, text.page_content AS content
UNWIND split(content, ' ') AS word
MERGE (w:Word {value: toLower(word)})
MERGE (c)-[:CONTAINS]->(w)
"""
tx.run(query, pdf_name=pdf_name, texts=[
{"page_content": t.page_content, "metadata": t.metadata}
for t in texts
])
# Create graph index and structure
with driver.session() as session:
session.execute_write(create_vector_index)
session.execute_write(create_document_graph, texts, pdf_path)
# Close driver
driver.close()# Create function for vector index in Neo4j after the graph representation is complete below
def create_vector_index(tx):
query = """
CREATE VECTOR INDEX pdf_content_index IF NOT EXISTS
FOR (c:Content)
ON (c.embedding)
OPTIONS {indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}
"""
tx.run(query)
# Function for Neo4j graph creation
def create_document_graph(tx, texts, pdf_name):
query = """
MERGE (d:Document {name: $pdf_name})
WITH d
UNWIND $texts AS text
CREATE (c:Content {text: text.page_content, page: text.metadata.page})
CREATE (d)-[:HAS_CONTENT]->(c)
WITH c, text.page_content AS content
UNWIND split(content, ' ') AS word
MERGE (w:Word {value: toLower(word)})
MERGE (c)-[:CONTAINS]->(w)
"""
tx.run(query, pdf_name=pdf_name, texts=[
{"page_content": t.page_content, "metadata": t.metadata}
for t in texts
])
# Create graph index and structure
with driver.session() as session:
session.execute_write(create_vector_index)
session.execute_write(create_document_graph, texts, pdf_path)
# Close driver
driver.close()Setup OpenAI for retrieval as well as embeddings:
# Define model for retrieval
llm = ChatOpenAI(model_name="gpt-3.5-turbo", openai_api_key=openai_api_key)
# Setup embeddings model w default OAI embeddings
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)Setup 3 retrievers to test:
Neo4j with reference to its index
Neo4j without reference to its index so it created embeddings from Neo4j as it was stored
FAISS to setup a non-Neo4j vector database on the same chunked document as a baseline
# Neo4j retriever setup using Neo4j, OAI embeddings model using Neo4j index
neo4j_vector_store = Neo4jVector.from_existing_index(
embeddings,
url=neo4j_url,
username=neo4j_user,
password=neo4j_password,
index_name="pdf_content_index",
node_label="Content",
text_node_property="text",
embedding_node_property="embedding"
)
neo4j_retriever = neo4j_vector_store.as_retriever(search_kwargs={"k": 2})
# OpenAI retriever setup using Neo4j, OAI embeddings model NOT using Neo4j index
openai_vector_store = Neo4jVector.from_documents(
texts,
embeddings,
url=neo4j_url,
username=neo4j_user,
password=neo4j_password
)
openai_retriever = openai_vector_store.as_retriever(search_kwargs={"k": 2})
# FAISS retriever setup - OAI embeddings model baseline for non Neo4j vector store touchpoint
faiss_vector_store = FAISS.from_documents(texts, embeddings)
faiss_retriever = faiss_vector_store.as_retriever(search_kwargs={"k": 2})Created ground truth from PDF for RAGAS eval (N = 100).
Using an OpenAI model for the ground truth, but also used OpenAI models as the default for retrieval in all variants, so no real bias introduced when creating the ground truth (outside of OpenAI training data!).
# Move to N = 100 for more Q&A ground truth
def create_ground_truth2(texts: List[Union[str, Document]], num_questions: int = 100) -> List[Dict]:
llm_ground_truth = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.7)
# Function to extract text from str or Document
def get_text(item):
if isinstance(item, Document):
return item.page_content
return item
# Split long texts into smaller chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_text(' '.join(get_text(doc) for doc in texts))
ground_truth2 = []
question_prompt = ChatPromptTemplate.from_template(
"Given the following text, generate {num_questions} diverse and specific questions that can be answered based on the information in the text. "
"Provide the questions as a numbered list.\n\nText: {text}\n\nQuestions:"
)
all_questions = []
for split in all_splits:
response = llm_ground_truth(question_prompt.format_messages(num_questions=3, text=split))
questions = response.content.strip().split('\n')
all_questions.extend([q.split('. ', 1)[1] if '. ' in q else q for q in questions])
random.shuffle(all_questions)
selected_questions = all_questions[:num_questions]
llm = ChatOpenAI(temperature=0)
for question in selected_questions:
answer_prompt = ChatPromptTemplate.from_template(
"Given the following question, provide a concise and accurate answer based on the information available. "
"If the answer is not directly available, respond with 'Information not available in the given context.'\n\nQuestion: {question}\n\nAnswer:"
)
answer_response = llm(answer_prompt.format_messages(question=question))
answer = answer_response.content.strip()
context_prompt = ChatPromptTemplate.from_template(
"Given the following question and answer, provide a brief, relevant context that supports this answer. "
"If no relevant context is available, respond with 'No relevant context available.'\n\n"
"Question: {question}\nAnswer: {answer}\n\nRelevant context:"
)
context_response = llm(context_prompt.format_messages(question=question, answer=answer))
context = context_response.content.strip()
ground_truth2.append({
"question": question,
"answer": answer,
"context": context,
})
return ground_truth2
ground_truth2 = create_ground_truth2(texts)Created a RAG chain for each retrieval method.
# RAG chain works for each retrieval method
def create_rag_chain(retriever):
template = """Answer the question based on the following context:
{context}
Question: {question}
Answer:"""
prompt = PromptTemplate.from_template(template)
return (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Calling the function for each method
neo4j_rag_chain = create_rag_chain(neo4j_retriever)
faiss_rag_chain = create_rag_chain(faiss_retriever)
openai_rag_chain = create_rag_chain(openai_retriever)Then ran evaluation on each RAG chain using all 4 metrics from RAGAS (context relevancy and context recall metrics evaluate the RAG retrieval, while answer relevancy and faithfulness metrics evaluate the full prompt response, against ground truth)
# Eval function for RAGAS at N = 100
async def evaluate_rag_async2(rag_chain, ground_truth2, name):
splitter = TokenTextSplitter(chunk_size=500, chunk_overlap=50)
generated_answers = []
for item in ground_truth2:
question = splitter.split_text(item["question"])[0]
try:
answer = await rag_chain.ainvoke(question)
except AttributeError:
answer = rag_chain.invoke(question)
truncated_answer = splitter.split_text(str(answer))[0]
truncated_context = splitter.split_text(item["context"])[0]
truncated_ground_truth = splitter.split_text(item["answer"])[0]
generated_answers.append({
"question": question,
"answer": truncated_answer,
"contexts": [truncated_context],
"ground_truth": truncated_ground_truth
})
dataset = Dataset.from_pandas(pd.DataFrame(generated_answers))
result = evaluate(
dataset,
metrics=[
context_relevancy,
faithfulness,
answer_relevancy,
context_recall,
]
)
return {name: result}
async def run_evaluations(rag_chains, ground_truth2):
results = {}
for name, chain in rag_chains.items():
result = await evaluate_rag_async(chain, ground_truth2, name)
results.update(result)
return results
def main(ground_truth2, rag_chains):
# Get event loop
loop = asyncio.get_event_loop()
# Run evaluations
results = loop.run_until_complete(run_evaluations(rag_chains, ground_truth2))
return results
# Run main function for N = 100
if __name__ == "__main__":
rag_chains = {
"Neo4j": neo4j_rag_chain,
"FAISS": faiss_rag_chain,
"OpenAI": openai_rag_chain
}
results = main(ground_truth2, rag_chains)
for name, result in results.items():
print(f"Results for {name}:")
print(result)
print()Developed a function to calculate confidence intervals at 95%, providing a measure of uncertainty for the similarity between LLM retrievals and ground truth, however since the results were already one value, I did not use the function and confirmed the directional differences when the same delta magnitudes and pattern was observed after rerunning multiple times.
# Plot CI - low sample size due to Q&A constraint at 100
def bootstrap_ci(data, num_bootstraps=1000, ci=0.95):
bootstrapped_means = [np.mean(np.random.choice(data, size=len(data), replace=True)) for _ in range(num_bootstraps)]
return np.percentile(bootstrapped_means, [(1-ci)/2 * 100, (1+ci)/2 * 100])Created a function to plot bar plots, initially with estimated error.
# Function to plot
def plot_results(results):
name_mapping = {
'Neo4j': 'Neo4j with its own index',
'OpenAI': 'Neo4j without using Neo4j index',
'FAISS': 'FAISS vector db (not knowledge graph)'
}
# Create a new OrderedDict
ordered_results = OrderedDict()
ordered_results['Neo4j with its own index'] = results['Neo4j']
ordered_results['Neo4j without using Neo4j index'] = results['OpenAI']
ordered_results['Non-Neo4j FAISS vector db'] = results['FAISS']
metrics = list(next(iter(ordered_results.values())).keys())
chains = list(ordered_results.keys())
fig, ax = plt.subplots(figsize=(18, 10))
bar_width = 0.25
opacity = 0.8
index = np.arange(len(metrics))
for i, chain in enumerate(chains):
means = [ordered_results[chain][metric] for metric in metrics]
all_values = list(ordered_results[chain].values())
error = (max(all_values) - min(all_values)) / 2
yerr = [error] * len(means)
bars = ax.bar(index + i*bar_width, means, bar_width,
alpha=opacity,
color=plt.cm.Set3(i / len(chains)),
label=chain,
yerr=yerr,
capsize=5)
for bar in bars:
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height,
f'{height:.2f}', # Changed to 2 decimal places
ha='center', va='bottom', rotation=0, fontsize=18, fontweight='bold')
ax.set_xlabel('RAGAS Metrics', fontsize=16)
ax.set_ylabel('Scores', fontsize=16)
ax.set_title('RAGAS Evaluation Results with Error Estimates', fontsize=26, fontweight='bold')
ax.set_xticks(index + bar_width * (len(chains) - 1) / 2)
ax.set_xticklabels(metrics, rotation=45, ha='right', fontsize=14, fontweight='bold')
ax.legend(loc='upper right', fontsize=14, bbox_to_anchor=(1, 1), ncol=1)
plt.ylim(0, 1)
plt.tight_layout()
plt.show()Finally, plotted these metrics.
To facilitate a focused comparison, key parameters such as document chunking, embeddings model, and retrieval model were held constant across experiments. CI was not plotted, and while I normally would plot that, I feel comfortable knowing this pattern after seeing it hold true after multiple reruns in this case (this presumes a level of uniformity to the data). So, caveat is that the results are pending that statistical window of difference.
When rerunning, the patterns of relative scores at repeated runs consistently showed negligible variability (surprisingly), and after running this analysis a few times by accident due to resource time-outs, the patterns stayed consistent and I am generally ok with this result.
# Plot
plot_results(results)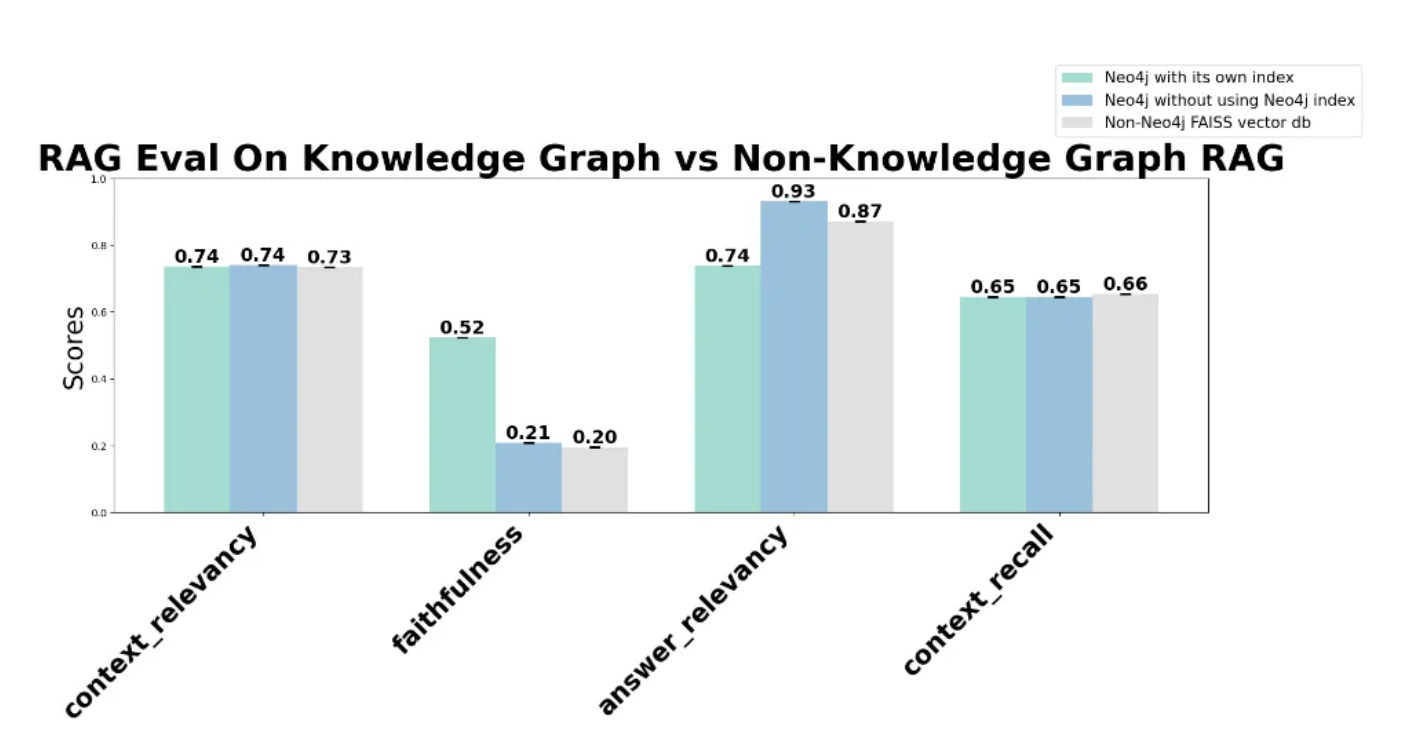
This shows a similar context relevancy between Neo4j and FAISS, as well as a similar context recall - stay tuned for Part 2, when I compare the nodes and edges created by an LLM within Neo4j with the same FAISS baseline.
reate_ground_truth2 is creating a "model-generated ground truth" rather than a true ground truth based on source documents. I mean, the questions are grounded in the source material, but the answers come from the model's general knowledge. So It's not truly a "ground truth" in the traditional sense. Right?
Core of the GraphRAG Project:
1. Entity Knowledge Graph Generation: Initially, a large language model (LLM) is used to extract entities and their interrelations from source documents, creating an entity knowledge graph.
2. Community Summarization: Related entities are further grouped into communities, and summaries are generated for each community. These summaries serve as partial answers during queries.
3. Final Answer Generation: For user questions, partial answers are extracted from the community summaries and then re-summarized to form the final answer.
This approach not only enhances the comprehensiveness and diversity of answers but also demonstrates higher efficiency and scalability when handling large-scale textual data.