Querying AI and Cloud Trends: Azure and OpenAI Dominate but Growth Slows, Amazon May Have Peaked
Cutting through the AI hype to query actual developer usage (with presumptions), for prioritization of safety tools and guidance for partnerships.

TLDR
AI development now appears as linear growth, not exponential (surge in March 2024 followed by rapid decline, now slower linear growth).
Azure/OpenAI dominance: this included OpenAI models but overall Azure shows 20x more new repos each month than the next leading hyperscaler.
Amazon Bedrock growth may have peaked in June 2024 (slightly exponential until then).
Introduction - what did I query?
I leveraged GitHub repository creation data to analyze adoption trends in AI and cloud computing adoption. Code below, analysis follows.
Note on caveats:
Despite obvious limitations, this method offers a unique view to developer adoption. Google Cloud and/or Microsoft formerly enabled querying of code within pages, which would have enabled a count of distinct import statements, but at some point recently this was disabled, therefore only leaving the repo names as queryable.
While imperfect, looking at repo creation provides enough data to challenge prevailing market narratives.
First, the notebook setup:
It’s only possible to use Google Cloud Platform (GCP) and BigQuery to access and query the GitHub data archive, so installed these packages (used colab initially, now parked in github).
# Install packages
!pip install -q pandas seaborn matplotlib google-cloud-bigquery
# Imports
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from google.cloud import bigquery
from google.oauth2 import service_accountQuery from GCP out of BigQuery:
The following SQL extracts relevant data by categorizing repositories related to specific AI and cloud technologies, then aggregates repository creation counts by creation month.
Dependent on some manual investigation of the right python package names.
query = """
WITH ai_repos AS (
SELECT
repo.name AS repo_name,
EXTRACT(DATE FROM created_at) AS creation_date,
CASE
WHEN LOWER(repo.name) LIKE '%bedrock%' THEN 'bedrock'
WHEN LOWER(repo.name) LIKE '%vertex%' THEN 'vertex'
WHEN LOWER(repo.name) LIKE '%openai%' THEN 'openai'
WHEN LOWER(repo.name) LIKE '%anthropic%' THEN 'anthropic'
WHEN LOWER(repo.name) LIKE '%langchain%' THEN 'langchain'
WHEN LOWER(repo.name) LIKE '%azure%' THEN 'azure'
WHEN LOWER(repo.name) LIKE '%llamaindex%' THEN 'llamaindex'
WHEN LOWER(repo.name) LIKE '%equinix%' THEN 'equinix'
WHEN LOWER(repo.name) LIKE '%neo4j%' THEN 'neo4j'
WHEN LOWER(repo.name) LIKE '%mongo%' THEN 'pymongo'
WHEN LOWER(repo.name) LIKE '%elasticsearch%' THEN 'elasticsearch'
WHEN (LOWER(repo.name) LIKE '%boto3%' OR LOWER(repo.name) LIKE '%amazon%' )THEN 'boto3'
WHEN (LOWER(repo.name) LIKE '%ayx%' OR LOWER(repo.name) LIKE '%alteryx%') THEN 'ayx'
WHEN LOWER(repo.name) LIKE '%snowflake%' THEN 'snowflake'
WHEN LOWER(repo.name) LIKE '%c3ai%' THEN 'c3ai'
WHEN LOWER(repo.name) LIKE '%dataiku%' THEN 'dataiku'
WHEN LOWER(repo.name) LIKE '%salesforce%' THEN 'salesforce_einstein'
WHEN LOWER(repo.name) LIKE '%qlik%' THEN 'qlik'
WHEN LOWER(repo.name) LIKE '%palantir%' THEN 'palantir_foundry'
WHEN LOWER(repo.name) LIKE '%cuda%' THEN 'nvidia_cuda'
WHEN LOWER(repo.name) LIKE '%openvino%' THEN 'intel_openvino'
WHEN LOWER(repo.name) LIKE '%clarifai%' THEN 'clarifai'
WHEN LOWER(repo.name) LIKE '%twilio%' THEN 'twilio'
WHEN LOWER(repo.name) LIKE '%oracle%' THEN 'oracle_ai'
WHEN (LOWER(repo.name) LIKE '%llama%' and LOWER(repo.name) NOT LIKE '%llamaindex%' AND LOWER(repo.name) NOT LIKE '%ollama%') THEN 'llama'
WHEN LOWER(repo.name) LIKE '%huggingface%' THEN 'huggingface'
WHEN LOWER(repo.name) LIKE '%nemo%' THEN 'nvidia'
WHEN (LOWER(repo.name) LIKE '%nimble%' OR LOWER(repo.name) LIKE '%hpe%' OR LOWER(repo.name) LIKE '%greenlake%') THEN 'hpe'
WHEN LOWER(repo.name) LIKE '%monday%' THEN 'monday'
WHEN LOWER(repo.name) LIKE '%zoom%' THEN 'zoom'
WHEN LOWER(repo.name) LIKE '%asana%' THEN 'asana'
WHEN LOWER(repo.name) LIKE '%zapier%' THEN 'zapier'
WHEN LOWER(repo.name) LIKE '%gitlab%' THEN 'gitlab'
WHEN LOWER(repo.name) LIKE '%smartsheet%' THEN 'smartsheet'
WHEN LOWER(repo.name) LIKE '%uipath%' THEN 'uipath'
WHEN LOWER(repo.name) LIKE '%braze%' THEN 'braze'
WHEN (LOWER(repo.name) LIKE '%junos%' OR LOWER(repo.name) LIKE '%juniper%') THEN 'hpe-juniper'
WHEN (LOWER(repo.name) LIKE '%google%' OR LOWER(repo.name) LIKE '%gemini%' or LOWER(repo.name) LIKE '%gemma%') THEN 'google'
WHEN LOWER(repo.name) LIKE '%ollama%' THEN 'ollama'
ELSE 'other'
END AS keyword_category
FROM
`githubarchive.day.20*`
WHERE
_TABLE_SUFFIX >= '230101'
AND _TABLE_SUFFIX NOT LIKE '%view%'
AND type = 'CreateEvent'
AND repo.name IS NOT NULL
AND (
LOWER(repo.name) LIKE '%bedrock%'
OR LOWER(repo.name) LIKE '%vertex%'
OR LOWER(repo.name) LIKE '%openai%'
OR LOWER(repo.name) LIKE '%anthropic%'
OR LOWER(repo.name) LIKE '%langchain%'
OR LOWER(repo.name) LIKE '%azure%'
OR LOWER(repo.name) LIKE '%llamaindex%'
OR LOWER(repo.name) LIKE '%neo4j%'
OR LOWER(repo.name) LIKE '%mongo%'
OR LOWER(repo.name) LIKE '%elasticsearch%'
OR LOWER(repo.name) LIKE '%boto3%'
OR LOWER(repo.name) LIKE '%equinix%'
OR LOWER(repo.name) LIKE '%ayx%'
OR LOWER(repo.name) LIKE '%amazon%'
OR LOWER(repo.name) LIKE '%alteryx%'
OR LOWER(repo.name) LIKE '%snowflake%'
OR LOWER(repo.name) LIKE '%c3ai%'
OR LOWER(repo.name) LIKE '%dataiku%'
OR LOWER(repo.name) LIKE '%salesforce%'
OR LOWER(repo.name) LIKE '%qlik%'
OR LOWER(repo.name) LIKE '%palantir%'
OR LOWER(repo.name) LIKE '%cuda%'
OR LOWER(repo.name) LIKE '%openvino%'
OR LOWER(repo.name) LIKE '%clarifai%'
OR LOWER(repo.name) LIKE '%twilio%'
OR LOWER(repo.name) LIKE '%oracle%'
OR LOWER(repo.name) LIKE '%llama%'
OR LOWER(repo.name) LIKE '%huggingface%'
OR LOWER(repo.name) LIKE '%nimble%'
OR LOWER(repo.name) LIKE '%hpe%'
OR LOWER(repo.name) LIKE '%greenlake%'
OR LOWER(repo.name) LIKE '%monday%'
OR LOWER(repo.name) LIKE '%asana%'
OR LOWER(repo.name) LIKE '%zapier%'
OR LOWER(repo.name) LIKE '%gitlab%'
OR LOWER(repo.name) LIKE '%smartsheet%'
OR LOWER(repo.name) LIKE '%uipath%'
OR LOWER(repo.name) LIKE '%braze%'
OR LOWER(repo.name) LIKE '%junos%'
OR LOWER(repo.name) LIKE '%juniper%'
OR LOWER(repo.name) LIKE '%ollama%'
OR LOWER(repo.name) LIKE '%google%'
OR LOWER(repo.name) LIKE '%gemini%'
OR LOWER(repo.name) LIKE '%gemma%'
OR LOWER(repo.name) LIKE '%nemo%'
OR LOWER(repo.name) LIKE '%zoom%'
)
)
SELECT
FORMAT_DATE('%Y-%m', creation_date) AS month,
keyword_category,
COUNT(DISTINCT repo_name) AS new_repo_count
FROM
ai_repos
GROUP BY
month, keyword_category
ORDER BY
month, keyword_category
"""Then extract, load, transform, etc..
Just created a pivot table with the right format..
# Query output to DF, create pivot
df = client.query(query).to_dataframe()
df['month'] = pd.to_datetime(df['month'])
df_pivot = df.pivot(index='month', columns='keyword_category', values='new_repo_count')
df_pivot.sort_index(inplace=True)
# Remove the current month to preserve data trend by month
df_pivot = df_pivot.iloc[:-1] Next, plotted the data:
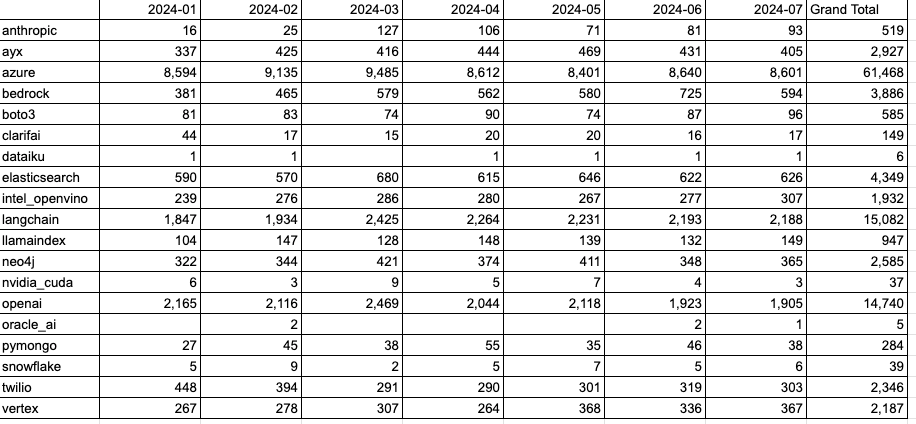
First time I’d tried this, I’d had to throw Azure to a secondary axis since it was 20x that of the next repo.
# Define color palette
colors = sns.color_palette("husl", n_colors=len(df_pivot.columns))
# Create plot
fig, ax1 = plt.subplots(figsize=(16, 10))
ax2 = ax1.twinx()
lines1 = []
labels1 = []
lines2 = []
labels2 = []
# Plot each keyword as a line, excluding 'azure' for separate axis
for keyword, color in zip([col for col in df_pivot.columns if col != 'azure'], colors):
line, = ax1.plot(df_pivot.index, df_pivot[keyword], linewidth=2.5, color=color, label=keyword)
lines1.append(line)
labels1.append(keyword)
# Plot 'azure' on the secondary axis
if 'azure' in df_pivot.columns:
line, = ax2.plot(df_pivot.index, df_pivot['azure'], linewidth=2.5, color='red', label='azure')
lines2.append(line)
labels2.append('azure')
# Customize the plot
ax1.set_title("GitHub Repository Creation Trends by AI Keyword", fontsize=24, fontweight='bold', pad=20)
ax1.set_xlabel("Repo Creation Month", fontsize=18, labelpad=15)
ax1.set_ylabel("New Repository Count (Non-Azure)", fontsize=18, labelpad=15)
ax2.set_ylabel("New Repository Count (Azure)", fontsize=18, labelpad=15)
# Format x-axis to show dates nicely
ax1.xaxis.set_major_formatter(DateFormatter("%Y-%m"))
plt.setp(ax1.xaxis.get_majorticklabels(), rotation=45, ha='right')
# Adjust tick label font sizes
ax1.tick_params(axis='both', which='major', labelsize=14)
ax2.tick_params(axis='both', which='major', labelsize=14)
# Adjust layout
plt.tight_layout()
# Create a single legend for both axes
fig.legend(lines1 + lines2, labels1 + labels2, loc='center left', bbox_to_anchor=(1.05, 0.5), fontsize=12)
# Adjust subplot parameters to give specified padding
plt.subplots_adjust(right=0.85)Results were interesting - since each month shows new repos created, Azure was exponential until March 2024, then declined quickly - is now linear growth since May 2024.
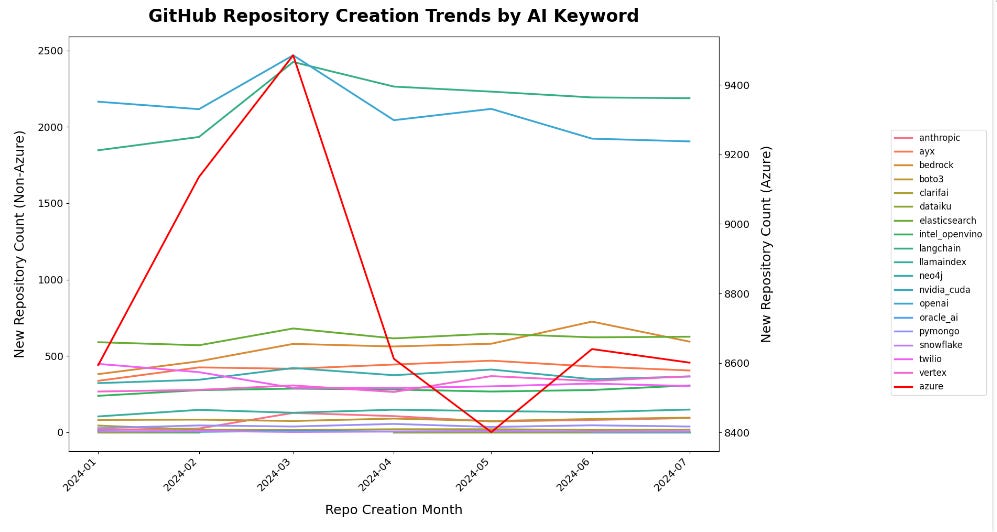
Re-plotted the data for clarity on smaller movements:
With the top 3 repos removed, it’s easier to see the scale - Amazon Bedrock clearly shows steadier adoption but appears to peak in June 2024. Note that some packages are not meant to show adoption, since these are public packages (e.g. Snowflake, Nvidia CUDA), and public repos.
# Isolate the top 3 to remove
top_3 = df_pivot.mean().nlargest(3).index
df_pivot_filtered = df_pivot.drop(columns=top_3)
fig, ax = plt.subplots(figsize=(16, 10))
for keyword, color in zip(df_pivot_filtered.columns, colors[:len(df_pivot_filtered.columns)]):
ax.plot(df_pivot_filtered.index, df_pivot_filtered[keyword], linewidth=2.5, color=color, label=keyword)
ax.set_title("GitHub Repository Creation Trends by AI Keyword (Excluding Top 3 Packages)", fontsize=24, fontweight='bold', pad=20)
ax.set_xlabel("Repo Creation Month", fontsize=18, labelpad=15)
ax.set_ylabel("New Repository Count", fontsize=18, labelpad=15)
ax.xaxis.set_major_formatter(DateFormatter("%Y-%m"))
plt.setp(ax.xaxis.get_majorticklabels(), rotation=45, ha='right')
ax.tick_params(axis='both', which='major', labelsize=14)
# Adjust layout
plt.tight_layout()
# Place legend outside the plot
ax.legend(loc='center left', bbox_to_anchor=(1.05, 0.5), fontsize=12)
# Adjust subplot parameters to give specified padding
plt.subplots_adjust(right=0.85)
plt.show()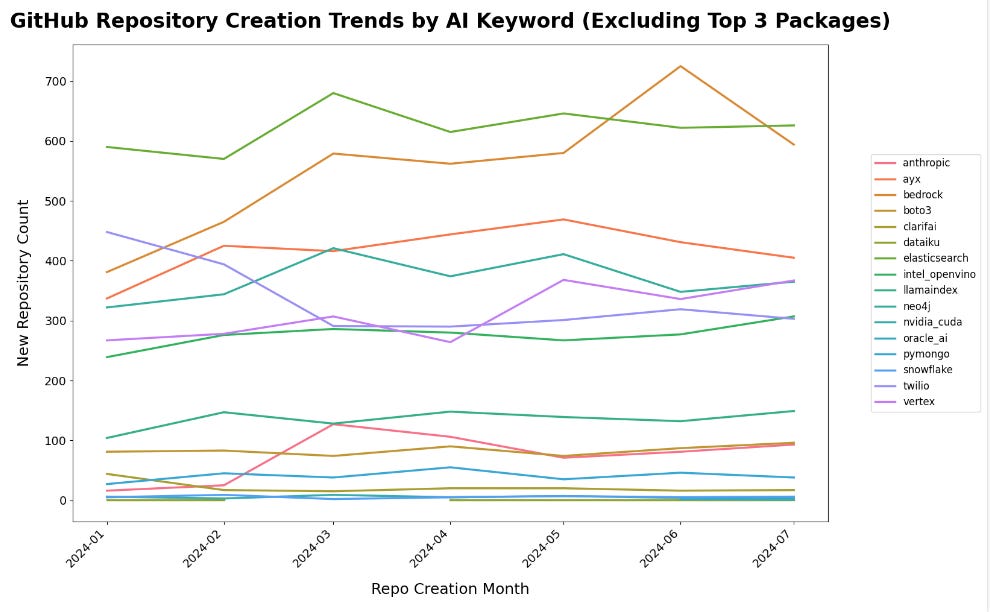
Takeaways:
Very large disparity between the smaller packages and those from ‘Big Tech’.
Azure and OpenAI dominate but growth is slowed.
Amazon may have peaked in June 2024.
More to come, stay tuned on more parts to this.
FYI the data is below, showing where obvious package names might not reflect the entire usage of the tool (e.g. Nvidia, Snowflake) - note the many biases and caveats (one repo might contain x scripts etc), so this assumes a new (and public) repo is growth.